Web サーバの作成 - HTTP API 入門
Web サーバーを作るなんて難しくて良くわからない、という方も多いと思いますが、 Windows には 「Web サーバーを簡単に作る」ための便利な API である、HTTP API があります。 これを使えば HTTP に関する基本的な知識さえあれば、Web サーバーを作ることが出来ます。
ここではその使い方をご紹介します。
ちなみに、HTTP API のバージョン 2 が公開されていますので、新しくコードを書くなら、
ぜひそちらもチェックしてください。
関連記事: HTTP サーバー API 2.0 を試してみよう
はじめに
Windows XP SP2 から HTTP API という、Web サーバ作成用の API が使用可能になりました。この資料では単純な Web サーバのサンプルコードを示しながら、HTTP API の利用方法を説明します。
さらに Vista や Windows Server 2008 以降をターゲットにする場合は、 IIS 7.0 の HWC を 利用するのもテです。(結局 IIS 7.0 は HTTP API を利用しているわけですが...)
HTTP API 概要
Windows Server 2003 から HTTP API という Web サーバー作成用の API が使用可能となりました。当初 HTTP API を利用できるのは Windows Server 2003 のみでしたが、後に Windows XP SP2 でもサポートされるようになったため、開発作業が大変容易となりました。
HTTP API はカーネルモードで実行されるドライバー http.sys として実装されており、httpapi.dll を通して http.sys と通信することによってユーザープログラムから利用します。http.sys で実装されると聞くと何かあったときはブルースクリーンが心配されると思うかもしれませんが、現在のところ HTTP API を利用する代表格ともいえる IIS6 でもそのようなクリティカルな問題は聞いたことが無いので、そこまで心配しなくて良いでしょう。
さて、早速プログラミングの手順について概要を説明します。基本的な手順は以下の通りです。
| 操作 | API |
| 1. HTTP API を初期化 | HttpInitialize |
| 2. リクエストキューの作成 | HttpCreateHttpHandle |
| 3. リクエストキューに URL を追加 | HttpAddUrl |
| 4. HTTP リクエストを受信&読み込み | HttpReceiveHttpRequest |
| 5. HTTP レスポンスの送信 | HttpSendHttpResponse |
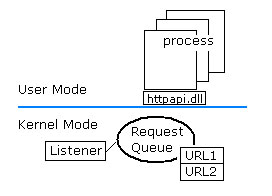
リクエストキューのイメージとしては、上図のように考えておけばよいでしょう。青い線の下側がカーネルモード (http.sys) で、上側が HTTP API を利用するプロセスを表しています。リクエストキューは http.sys の中に作成されます。キューは複数作成することが可能です。どのリクエストキューでどの URL を処理するかを決定できるようにするために、URL は明示的にキューと関連付けされます。
Web サーバの作成
なんと、これまでの説明だけで単純な Web サーバーは作成可能です。サンプルコード全体は以下からダウンロードして下さい。
単純な Web サーバサンプルコード [ssrv1.zip, makefile プロジェクト]
以前アップロードしていたファイルはそのままだとビルドできないことがわかりました。
ごめんなさい!
次の二点を行うことでビルド可能になるはずです。
- ssrv1.cpp に #include<stdio.h> を追加
- コンパイラオプションに /D_WIN32_WINNT=0x0600 (または 0x0501 等) を追加
新しいバージョンのサンプルコードは準備出来次第アップロードします。
サンプルコード中、キモとなるのは ssrv1.cpp ですから ssrv1.cpp についてコメントを追記しながら見ていきましょう。
HTTP API を使うためにヘッダーファイル http.h をインクルードしています。
#include <http.h>
#include "bldpath.h"
#include "debug.h"
HTTP のステータスラインに返す文字を定義します。このサンプルでは OK (200) と File Not Found(404) のみをサポートすることにします。
#define STATUS_MSG_FILE_NOT_FOUND ("File
Not Found")
#define STATUS_MSG_OK ("OK")
さらに 404 のときに返すボディも定義します。 まともなサーバーを作るならエラーメッセージも差し替え可能にすべきですが、ここでは単純化のために定数にしてあります。 お好みに応じて直してください。
#define STATUS_BODY_FILE_NOT_FOUND ("<html><body><h1>File not found</h1></body></html>")
このサンプルは単純なコンソールプログラムとして実装しています。開始は main (_tmain) から始まります。
int _tmain(int argc, _TCHAR* argv[]) {
HTTP API の初期化を行います。
ULONG
ulRet;
HTTPAPI_VERSION httpApiVersion =
HTTPAPI_VERSION_1;
ulRet = HttpInitialize
(
httpApiVersion, //
Version
HTTP_INITIALIZE_SERVER, // Flags
NULL); //
Reserved
リクエストキューを作成します。 HttpCreateHttpHandle なんて名前ではなく、HttpCreateRequestQueue という名前だったら良かったのに、と思うのは私だけではないでしょう。
HANDLE
hReqQueue = NULL;
ulRet = HttpCreateHttpHandle
(&hReqQueue, NULL);
リクエストキューに URL を登録します。登録する URL の構文に注意して下さい。ここでは、"+" を利用してこのマシンの全ての IP アドレス及びホスト名における TCP ポート 8080番へのリクエストを受け付けています。
ulRet = HttpAddUrl (hReqQueue, L"http://+:8080/", NULL);
もしここで L"http://localhost:8080"& nbsp;を指定すると、http://localhost:8080/ は受け付けますが http://127.0.0.1:8080/ は不正なリクエストと認識されます。 この機能は HTTP 1.1 のホストヘッダーをサポートする際に利用できます。
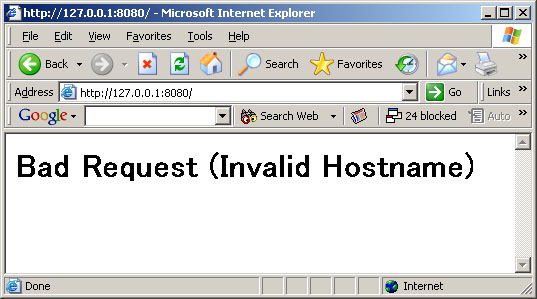
この応答は HTTP.SYS が返しています。
サンプルコードではこの後、無限ループに入り、HTTP リクエストの受け取りと応答を繰り返します。
while (1) {
HTTP_REQUEST_ID HttpRequestID = HTTP_NULL_ID;
PHTTP_REQUEST pHttpRequest;
BYTE pHttpHeaderBuffer [2048];
// 2kb
ULONG cbHttpHeaderBuffer;
ULONG cbBytesReceived = 0;
pHttpRequest = (PHTTP_REQUEST)
pHttpHeaderBuffer;
cbHttpHeaderBuffer = 2048;
HTTP リクエストの受信。受信するまでここでブロックします。受け取り用のバッファーは 2kb を指定しています。
ulRet = HttpReceiveHttpRequest (
hReqQueue,
HttpRequestID,
0,
pHttpRequest,
cbHttpHeaderBuffer,
&cbBytesReceived,
NULL);
基本的に HttpReceiveHttpRequest は HTTP リクエストヘッダーのみを受信します。 この点がソケットを操作するときと比べてプログラミングが楽です。 わざわざヘッダとボディの区切りをチェックする必要がありません。
ボディ部があるかどうかチェックします。ボディが存在する場合、HTTP_REQUEST の Flags にて、HTTP_REQUEST_FLAG_MORE_ENTITY_BODY_EXISTS がセットされます。
if ( HTTP_REQUEST_FLAG_MORE_ENTITY_BODY_EXISTS & pHttpRequest->Flags ) {
ボディが存在するときは、HttpReceiveRequestEntityBody で読み込みます。 ボディ部が読み込み終わると、HttpReceiveRequestEntityBody が ERROR_HANDLE_EOF を返します。
for (bool bContinue = true; bContinue; ) {
BYTE pHttpBodyBuffer [16];
ULONG cbHttpBodyBuffer = 16;
cbBytesReceived = 0;
ulRet = HttpReceiveRequestEntityBody (
hReqQueue,
pHttpRequest->RequestId,
0, // Reserved
pHttpBodyBuffer,
cbHttpBodyBuffer,
&cbBytesReceived,
NULL);
...
switch ( ulRet ) {
case NO_ERROR: // 正常に読み込んだ (しかしもっとデータがあるかもしれない)
printf ( "NO_ERROR\n" );
// dump the data
PrintHexDump ( cbBytesReceived, (PBYTE) pHttpBodyBuffer );
break;
case ERROR_HANDLE_EOF: // 全てのデータを読み込んだ
printf ( "ERROR_HANDLE_EOF\n" );
bContinue = false;
break;
default:
bContinue = false;
printf ("%u\n", ulRet );
}
}
}
実際にサンプルを実行してみれば、ここで何をしているかわかると思います。
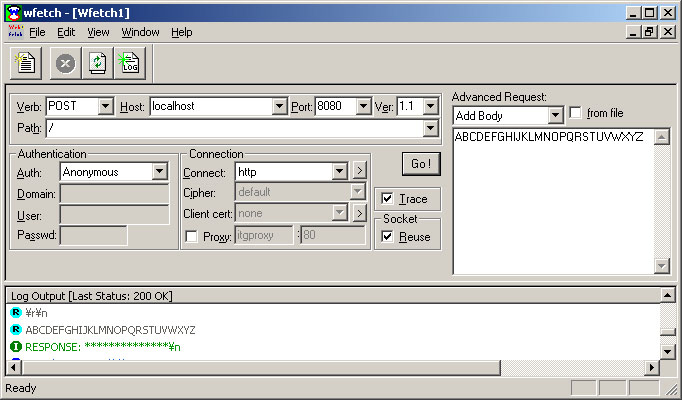
試しに WFetch を使って A ~ Z までの 26 文字を POST してみます。
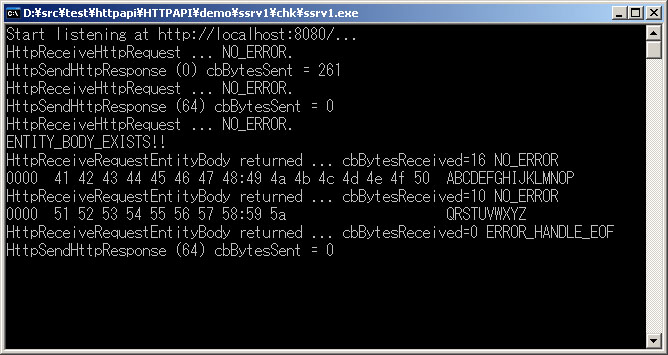
その結果、次のようなトレースが記録されました。サンプルでは 16 バイトの受け取りバッファを指定しているので、A ~ P までの 16 文字が最初の HttpReceiveRequestEntityBody 呼び出しで読み込まれ、二度目の HttpReceiveRequestEntityBody で Z までの残り 10 バイトが読み込まれています。最後まで読みきった場合にも、戻り値は NO_ERROR となります。Content-Length をチェックして cbBytesReceived の積算と比較してデータを読み込むのがまっとうなやり方でしょうが、ここではもう一度 HttpReceiveRequestEntityBody を呼び出して ERROR_HANDLE_EOF を出し、それを読み込みループの終了判定にしています。
次に HTTP レスポンス。
ここでははじめにデフォルトの属性を text/html と決めました。
HTTP_RESPONSE HttpResponse;
::ZeroMemory ( &HttpResponse, sizeof (HTTP_RESPONSE) );
HttpResponse.Version.MajorVersion = 1;
HttpResponse.Version.MinorVersion = 0;
HttpResponse.Headers.KnownHeaders[HttpHeaderContentType].pRawValue =
"text/html";
HttpResponse.Headers.KnownHeaders[HttpHeaderContentType].RawValueLength
= strlen ("text/html");
HTTP_DATA_CHUNK HttpDataChunk;
WCHAR pszFileName[MAX_PATH];
CHAR pszContentType [64];
ULONG cbContentType = sizeof ( pszContentType );
要求された URL は pHttpRequest->CookedUrl.pAbsPath に入ります。ここでは、ルートパスと URL パスからファイルを特定してそれを開き、さらにそのファイルハンドルを返す関数 GetFileHandleFromURL を実装しました。戻り値に INVALID_HANDLE_VALUE が返れば、ファイルが開けなかったことを示し、それ以外ならファイルが開けたと判定します。
一般的には、ファイルが開けない理由は、「ファイルが存在しないから」 という理由だけではなく、 アクセス権が原因である場合もあります。HTTP のステータスコードとしては通常この場合には 401 や 403 などを返すべきなのですが、ここでは簡便のため全て 404 としています。(401 は Authentication を要求することを、403 は Authorization の失敗を、それぞれ意味します)
HANDLE hFile = GetFileHandleFromURL
( // API ではないのでご注意。
L"C:\\Inetpub\\wwwroot",
pHttpRequest->CookedUrl.pAbsPath,
pszFileName,
//
ファイル名
MAX_PATH * sizeof
(WCHAR)); // ファイル名を受け取る
バッファ長
if ( INVALID_HANDLE_VALUE == hFile ) { // 'File Not Found'
// Server status
HttpResponse.StatusCode = 404;
HttpResponse.pReason = STATUS_MSG_FILE_NOT_FOUND;
HttpResponse.ReasonLength = strlen ( STATUS_MSG_FILE_NOT_FOUND );
"File Not Found" というメッセージはメモリブロックから返されるので、チャンクタイプとして HttpDataChunkFromMemory を指定します。その他に後述するように HttpDataChunkFromFileHandle 等があります。
HttpDataChunk.DataChunkType =
HttpDataChunkFromMemory;
HttpDataChunk.FromMemory.pBuffer = STATUS_BODY_FILE_NOT_FOUND;
HttpDataChunk.FromMemory.BufferLength = strlen (
STATUS_BODY_FILE_NOT_FOUND );
...
}
else {
// Server status
HttpResponse.StatusCode = 200;
HttpResponse.pReason = STATUS_MSG_OK;
HttpResponse.ReasonLength = strlen ( STATUS_MSG_OK );
200 の場合は、ファイルハンドルから直接応答します。このときのチャンクタイプは HttpDataChunkFromFileHandle です。Byte-Range に対応できるように、指定したファイルのバイト範囲を指定できます。コンテンツ全体を指定するにはサンプルのように HTTP_BYTE_RANGE_TO_EOF を指定します (StartingOffset は 0)。
HttpDataChunk.DataChunkType =
HttpDataChunkFromFileHandle;
HttpDataChunk.FromFileHandle.FileHandle = hFile;
HttpDataChunk.FromFileHandle.ByteRange.StartingOffset.QuadPart = 0;
HttpDataChunk.FromFileHandle.ByteRange.Length.QuadPart =
HTTP_BYTE_RANGE_TO_EOF;
// Content-Type
if ( GetContentType ( pszFileName, pszContentType,
&cbContentType ) ) {
HttpResponse.Headers.KnownHeaders [HttpHeaderContentType].pRawValue =
pszContentType;
HttpResponse.Headers.KnownHeaders
[HttpHeaderContentType].RawValueLength = cbContentType;
}
}
HttpResponse.EntityChunkCount = 1;
HttpResponse.pEntityChunks =
&HttpDataChunk;
ULONG cbBytesSent = 0;
ulRet = HttpSendHttpResponse (
hReqQueue,
pHttpRequest->RequestId,
HTTP_SEND_RESPONSE_FLAG_DISCONNECT,
&HttpResponse,
NULL,
&cbBytesSent,
NULL,
0,
NULL,
NULL);
printf ( "HttpSendHttpResponse (%u) cbBytesSent = %u\n", ulRet,
cbBytesSent );
// Close the file handle (if it's opened)
if ( INVALID_HANDLE_VALUE != hFile ) {
CloseHandle ( hFile );
}
} // loop
このサンプルではループを抜けることは無いので、クリーンアップコードは実行されない。が、一応書いておきました。
cleanup:
//
// clean up
//
// Remove URL
HttpRemoveUrl
(hReqQueue, L"http://+:8080/bar/");
// Close request queue
if ( hReqQueue ) {
CloseHandle
( hReqQueue );
}
// Terminate HTTP API
HttpTerminate
(HTTP_INITIALIZE_SERVER, NULL);
return 0;
}
以上、シングルスレッド+同期呼び出しを使用する単純な Web サーバーの作成を通して、HTTP API の基本的な利用方法について説明しました。
ぜひ、試しに自分で Web サーバーを書いてみてください!